CCF GESP 2026年3月认证 C++ 7级
一
单选题
第 1 题
假设⼀个算法时间复杂度的递推式是 $T(n)=2T(n−1)+1$ ($n$ 为正整数) ,且 $T(0)=1$,那么这个算法的时间复杂度是( )。
第 2 题
下面关于“唯⼀分解定理”和“素数筛法”的说法中,错误的是( )。
第 3 题
若字符串 A 与字符串 B 的最长公共子序列(LCS)长度为 5,则( )。
第 4 题
对于⼀棵包含 n 个顶点(n≥2)的树,其所有顶点的度数之和必定等于( )
第 5 题
关于哈希表(Hash Table)在不考虑扩容且采⽤简单均匀哈希函数的前提下,下列说法中错误的是( )。
第 6 题
深度优先搜索(DFS)在遍历图时,每当访问到某个顶点后,选择一个相邻的未访问顶点继续搜索,直到某个顶点的所有相邻顶点均已被访问,则退回到前一顶点继续搜索。该算法主要运用了( )。
第 7 题
下面程序的运行结果为( )。
#include <iostream>
#include <algorithm>
bool check(int n, int a[], int k, int dist) {
int cnt = 1;
int last = a[0];
for (int i = 1; i < n; i++) {
if (a[i] - last >= dist) {
cnt++;
last = a[i];
}
}
return cnt >= k;
}
int solve(int n, int a[], int k) {
std::sort(a, a + n);
int l = 0;
int r = a[n - 1] - a[0];
while (l < r) {
int mid = (l + r + 1) / 2;
if (check(n, a, k, mid))
l = mid;
else
r = mid - 1;
}
return l;
}
int main() {
int a[] = {1, 2, 8, 4, 9};
int n = 5;
int k = 3;
std::cout << solve(n, a, k) << std::endl;
return 0;
}
第 8 题
下面程序的时间复杂度是( ),假设数组 a 的值域范围是 D。
#include <iostream>
#include <algorithm>
bool check(int n, int a[], int k, int dist) {
int cnt = 1;
int last = a[0];
for (int i = 1; i < n; i++) {
if (a[i] - last >= dist) {
cnt++;
last = a[i];
}
}
return cnt >= k;
}
int solve(int n, int a[], int k) {
std::sort(a, a + n);
int l = 0;
int r = a[n - 1] - a[0];
while (l < r) {
int mid = (l + r + 1) / 2;
if (check(n, a, k, mid))
l = mid;
else
r = mid - 1;
}
return l;
}
int main() {
int a[] = {1, 2, 8, 4, 9};
int n = 5;
int k = 3;
std::cout << solve(n, a, k) << std::endl;
return 0;
}
第 9 题
某二叉树共有 10 个结点,记为 A~J,已知它的先序遍历序列为:A B D H I E C F J G,中序遍历序列为:H D I B E A F J C G,则该二叉树的后序遍历序列是( )。
第 10 题
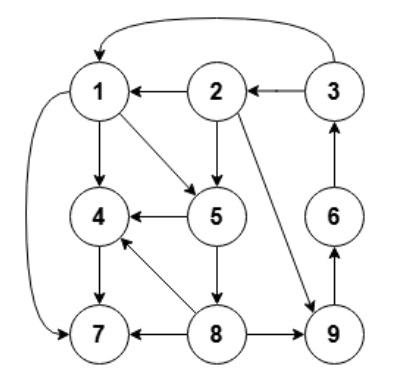
下面哪一个可能是下图的深度优先遍历序列( )。
第 11 题
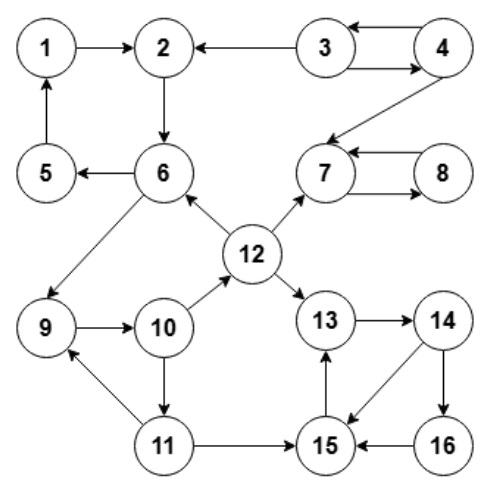
下面这个有向图的强连通分量的个数是( )。
第 12 题
关于泛洪算法(Flood Fill)的说法,正确的是( )。
第 13 题
有 6 个字符,它们出现的次数分别为: {2, 3, 3, 4, 6, 8} ,现在用哈夫曼编码为这些字符编码,最小加权路径长度 WPL(每个字符的出现次数 $\times$ 它的编码长度,再把每个字符结果加起来)的值为( )。
第 14 题
关于单链表、双链表和循环链表,下列说法正确的是( )。
第 15 题
下列关于树的遍历的说法中,正确的一项是( )。
单选题部分已到底了。